




 中国教育在线
中国教育在线



最近,视觉和语言的多模态任务,例如图像字幕和视觉问题解答(VQA),引起了学术界和工业界的广泛兴趣。但是,大多数现有的模型都专注于单个任务。深圳研究生院信息工程学院邹月娴教授课题组研究发现,这些任务存在一定的相似性,因此认为如果模型可以同时考虑这些多模态问题,则可以共同学习来自不同任务的不同知识,并且很有可能提高每个任务的效能。
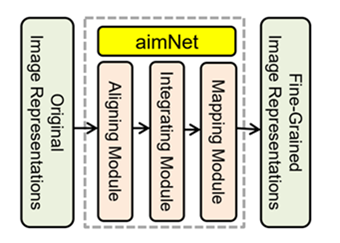
近日,邹月娴课题组的研究“Federated Learning for Vision-and-Language Grounding Problems”被在美国纽约举行的第34届人工智能发展协会(AAAI)人工智能会议(AAAI Conference on Artificial Intelligence, AAAI 2020)接收发表并以口头汇报(Oral)的形式进行了展示。该研究成果提出了一种联邦学习框架,可以从不同的任务中获得各种类型的图像表示,然后将它们融合在一起以形成细粒度的图像表示。这些图像表示融合了来自不同视觉和语言的多模态问题的有用图像表示,因此在单个任务中比单独的原始图像表示强大得多。为了学习这种图像表示,该课题组提出了对齐(Aligning)、集成(Integrating)和映射(Mapping)、网络(aimNet)。aimNet由一个对齐模块,一个集成模块和一个映射模块组成(如下图)。
课题组提出的集中式模型aimNet
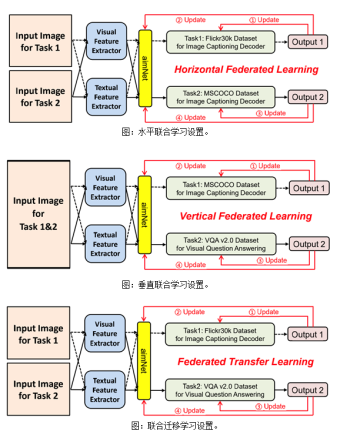
其中,对齐模块通过对提取的视觉和文本特征进行相互关注来构建对齐的图像表示,其能为显著图像区域提供了更清晰的语义描述。接下来,集成模块着重于通过自我注意机制集成视觉和文本特征,该机制捕获显著区域的分组和属性的搭配。最后,映射模块由两层非线性层组成,用于将学习到的细粒度图像表示映射到特定任务的特征域。各课题组提出的模块充分利用了图像中的所有有效信息,并将其作为输入传递给解码器,以生成有意义的句子或给出问题的准确答案。该课题组在两个图像字幕数据集和一个VQA数据集上,以及相应的三个联邦学习设置上,包括水平联合学习,垂直联合学习和联合迁移学习,进行实验用于验证该课题组的动机以及所提出方法的有效性。
2019级硕士生刘峰林为该论文第一作者,邹月娴为通讯作者,该工作得到了数字视频编解码技术国家工程实验室、深圳市发改委(数据科学与智能计算学科发展计划)和Aoto-PKUSZ联合实验室的支持。
① 凡本站注明“稿件来源:中国教育在线”的所有文字、图片和音视频稿件,版权均属本网所有,任何媒体、网站或个人未经本网协议授权不得转载、链接、转贴或以其他方式复制发表。已经本站协议授权的媒体、网站,在下载使用时必须注明“稿件来源:中国教育在线”,违者本站将依法追究责任。
② 本站注明稿件来源为其他媒体的文/图等稿件均为转载稿,本站转载出于非商业性的教育和科研之目的,并不意味着赞同其观点或证实其内容的真实性。如转载稿涉及版权等问题,请作者在两周内速来电或来函联系。
